Method
CoMo represents motions as pose codes, with each code defining the state of a specific body part at a given moment, e.g., "right arm straight". Leveraging pose codes as interpretable motion representations, the three main components of CoMo work jointly to effectively generate and edit motion: (1) The Motion Encoder-Decoder parses motions into sequences of pose codes and reconstructs them back into motions by learning a decoder; (2) The Motion Generator, a transformer-based model, generates pose codes conditioned on text inputs and LLM-generated fine-grained descriptions; (3) The Motion Editor uses LLM to modify and refine the pose codes based on editing instructions.
CoMo allows for intuitive, iterative adjustments to motion sequences generated from textual descriptions, which corrects and closely aligns the generated motions both temporally and spatially with the users’ creative intentions, making the process user-friendly and adaptable to diverse applications.
Do a karate kick.
Aim lower.
Dodge by squatting at the end.
A person does a handstand.
Keep legs close together.
Face the right instead.
A person swings a bat.
Hit higher.
Swing with less force.
Human Evaluation
54 users evaluated motion editing quality for editing scenarios that cover body part modification, add/delete actions edits, speed change and style/emotion change. Results show a clear preference (over 70% on average) for motion editing with CoMo when compared to baselines T2M-GPT [1] and FineMoGen [2].
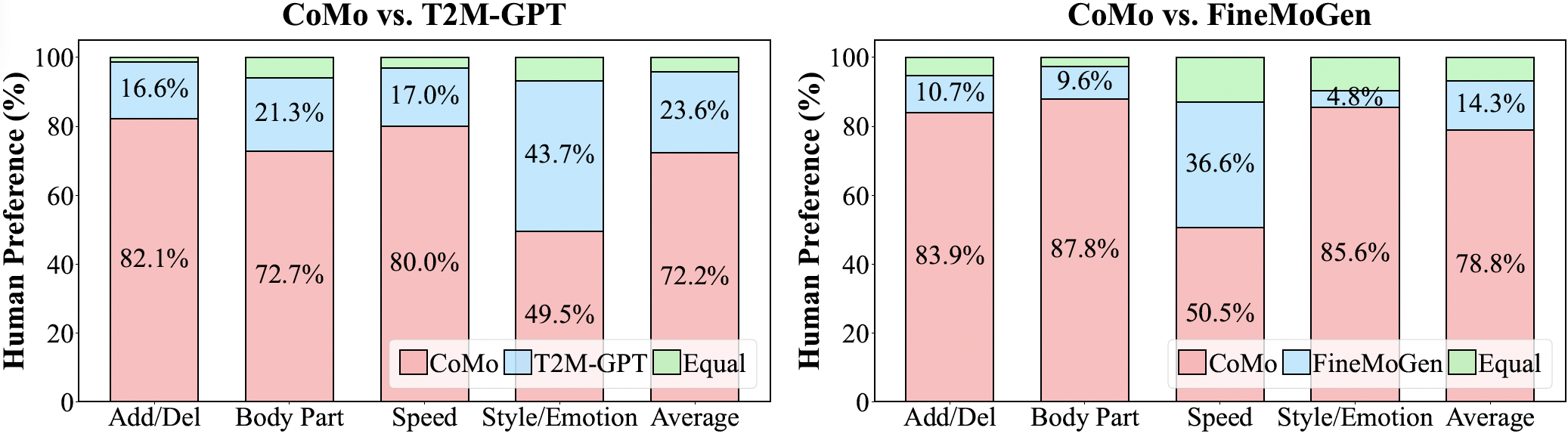
Comparison
Humans prefer CoMo for motion editing, especially in scenarios that modify fine-grained motion details. CoMo effectively achieves a motion edit according to the provided instruction while preserving key characteristics of the source motion.
Source Text: A person lowers their arms, and then moves them back up to shoulder height.
Edit Text: Keep knees more deeply bent.
Source Text: A person beginning to run in a straight line.
Edit Text: Raise left hand at the end.
Source Text: A person walks forward and then appears to bump into something, then continues walking forward.
Edit Text: Make the bump more dramatic.
Source Text: The person bent down and dodge something towards the left.
Edit Text: Bend down slower.
BibTeX
@misc{huang2024como,
title={CoMo: Controllable Motion Generation through Language Guided Pose Code Editing},
author={Yiming Huang and Weilin Wan and Yue Yang and Chris Callison-Burch and Mark Yatskar and Lingjie Liu},
year={2024},
eprint={2403.13900},
archivePrefix={arXiv},
primaryClass={cs.CV}
}